3 formas de rodar DeepSeek e Llama localmente
12 de fevereiro de 2025 · 4 min de leitura
Large Language Models (LLMs) mudaram o cenário de IA, e modelos menores estão avançando rapidamente. Com isso, já é possível rodar LLMs avançados até em PCs mais antigos e smartphones. Como ponto de partida, vamos ver três métodos para interagir localmente com Llama 3.3 ou DeepSeek.
Resumo rápido
- Pacote Python: use Ollama para chats simples ou em streaming com modelos como
deepseek-r1:1.5b. - API: use a API HTTP local do Ollama para integração flexível em qualquer linguagem.
- LangChain: construa aplicações avançadas como análise de documentos e busca contextual com embeddings e bases vetoriais.
Pré-requisitos
Antes de começar:
- Ollama instalado e em execução
Decisões, decisões...
Qual versão do modelo é pequena o suficiente para rodar localmente? Minha abordagem: testar. Comece da menor versão e vá subindo até entender o limite da sua máquina.
Para ver versões disponíveis no Ollama: https://ollama.com/search.
Por exemplo, para deepseek-r1, a menor versão disponível é 1.5b. No terminal:
ollama pull deepseek-r1:1.5b
Temos:
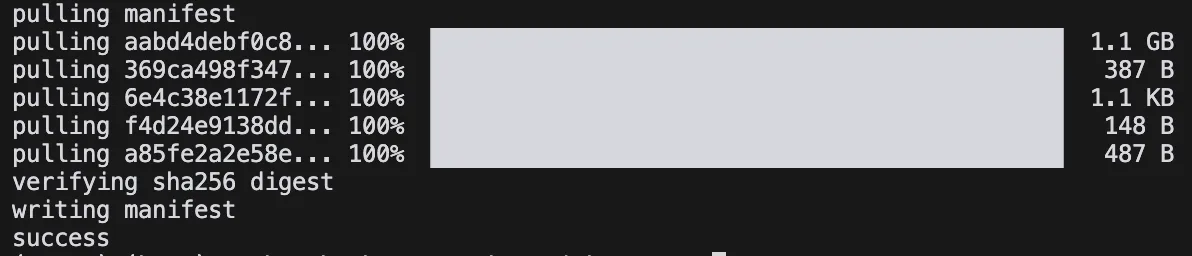
O modelo fica em pouco mais de 1,1 GB. Ótimo.
Para testar rapidamente:
ollama run deepseek-r1:1.5b
Saída:
>>> Send a message (/? for help)
Vamos enviar uma mensagem:
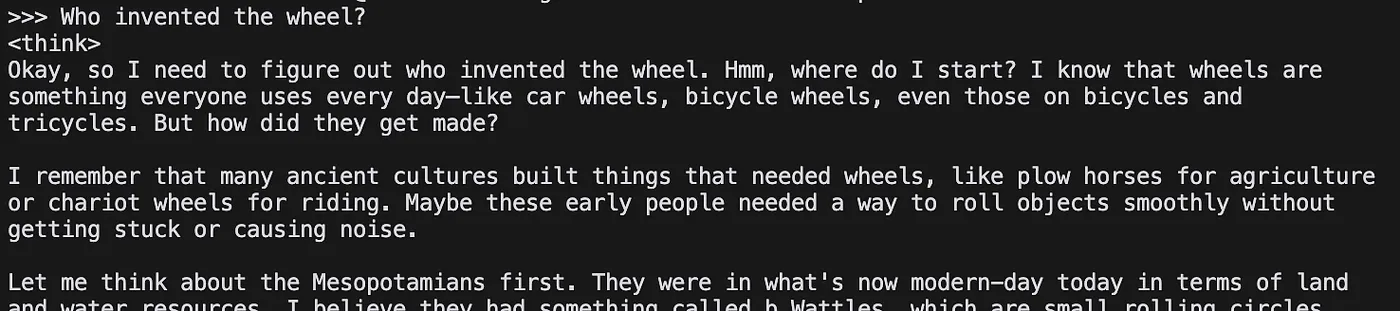
O resultado é impressionante.
Método 1: pacote Python do Ollama
O pacote Python do Ollama oferece uma forma direta de usar DeepSeek 1.5b em scripts Python ou notebooks.
import ollama
response = ollama.chat(
model="deepseek-r1:1.5b",
messages=[
{
"role": "user",
"content": "Tell me an interesting fact about elephants",
},
],
)
print(response["message"]["content"])
A resposta vem bem maior que 50 palavras (também testei a versão 32b com a mesma pergunta, sem ganho tão grande).
Vamos seguir para a parte de implementação.
Para streaming, use AsyncClient:
import asyncio
from ollama import AsyncClient
async def chat():
message = {
"role": "user",
"content": "Tell me an interesting fact about elephants"
}
async for part in await AsyncClient().chat(
model="deepseek-r1:1.5b", messages=[message], stream=True
):
print(part["message"]["content"], end="", flush=True)
# Run the async function
async def main():
await chat()
# Check if there's a running event loop and use it, otherwise create a new one
try:
loop = asyncio.get_running_loop()
except RuntimeError:
loop = None
if loop and loop.is_running():
asyncio.ensure_future(main())
else:
asyncio.run(main())
Método 2: usando a API do Ollama
Se você prefere APIs diretas ou quer integrar Llama/DeepSeek em apps não Python, o Ollama oferece uma API HTTP simples.
curl http://localhost:11434/api/chat -d '{
> "model": "deepseek-r1:1.5b",
> "messages": [
> {
> "role": "user",
> "content": "What are God Particles?"
> }
> ],
> "stream": false
> }'
Esse método é flexível para qualquer linguagem ou ferramenta com requisições HTTP.
Método 3: LangChain para aplicações avançadas
Para cenários mais complexos, principalmente análise de documentos e retrieval, LangChain integra muito bem com Ollama e Llama 3.2.
O snippet abaixo carrega documentos, cria embeddings e faz busca por similaridade com um artigo da Wikipedia sobre Thomas Jefferson salvo como Word.
Instale python-docx (por exemplo, pip install python-docx).
from langchain_community.document_loaders import DirectoryLoader, UnstructuredWordDocumentLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.llms import Ollama
from langchain_community.vectorstores import Chroma
# Load documents
loader = DirectoryLoader('/path/to/documents', glob="**/*.docx", loader_cls=UnstructuredWordDocumentLoader)
documents = loader.load()
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(documents)
# Create embeddings and vector store
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# Initialize LLama 3.2 1B
llm = Ollama(model="llama3.2:1b", base_url="http://localhost:11434")
# Perform a similarity search and generate a response
query = "What was the main accomplishment of Thomas Jefferson?"
similar_docs = vectorstore.similarity_search(query)
context = "\n".join([doc.page_content for doc in similar_docs])
response = llm(f"Context: {context}\nQuestion: {query}\nAnswer:")
print(response)
Resposta do modelo:

Não é perfeita, mas esse método permite criar aplicações que entendem e raciocinam sobre grandes volumes de texto usando Llama, DeepSeek e outros modelos.
Conclusão
Rodar localmente Llama 3.2, DeepSeek e outros modelos do Ollama abre muitas possibilidades para aplicações de IA.
Seja chat simples, integração via API ou análise documental avançada, esses três caminhos cobrem uma ampla faixa de casos de uso.
Use essas ferramentas com responsabilidade e ética.