3 modi per eseguire DeepSeek e Llama in locale
12 febbraio 2025 · 4 min di lettura
I Large Language Models (LLM) hanno rivoluzionato il panorama IA, e i modelli piccoli stanno crescendo rapidamente. Per questo oggi è possibile eseguire modelli avanzati anche su PC meno recenti e smartphone. Come punto di partenza, vediamo tre metodi per interagire localmente con Llama 3.3 o DeepSeek.
TL;DR
- Pacchetto Python: usa Ollama per chat semplici o in streaming con modelli come
deepseek-r1:1.5b. - API: usa la API HTTP locale di Ollama per integrazione flessibile in qualsiasi linguaggio.
- LangChain: crea applicazioni avanzate (analisi documentale, retrieval) con embeddings e vector store.
Prerequisiti
Prima di iniziare, assicurati di avere:
- Ollama installato e in esecuzione
Scelte, scelte...
Quale versione del modello è abbastanza piccola da girare sul tuo computer? Il mio approccio: prova sul campo. Parti dalla versione più piccola e sali finché capisci quante risorse può gestire la tua macchina.
Per vedere le versioni disponibili su Ollama: https://ollama.com/search.
Per deepseek-r1, ad esempio, la versione minima disponibile è 1.5b. Quindi nel terminale:
ollama pull deepseek-r1:1.5b
Otteniamo:
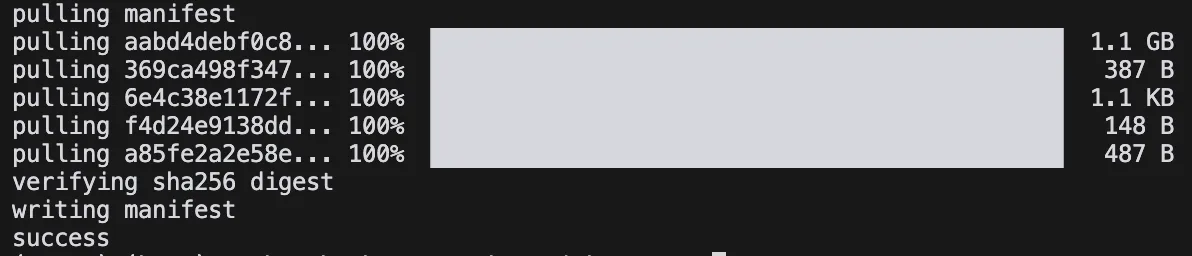
Il modello occupa poco più di 1.1 GB. Non male.
Per provarlo velocemente:
ollama run deepseek-r1:1.5b
Output:
>>> Send a message (/? for help)
Inviamo un messaggio:
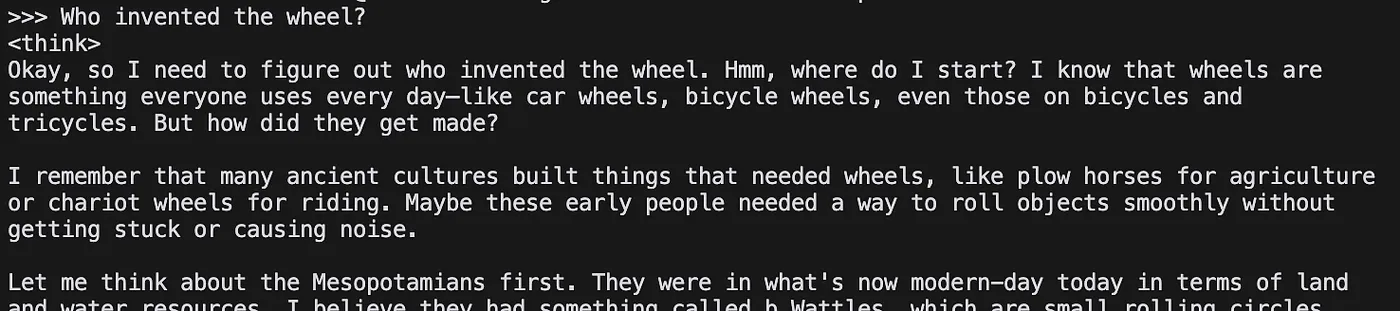
Il risultato è notevole.
Metodo 1: pacchetto Python Ollama
Il pacchetto Python di Ollama offre un modo diretto per integrare DeepSeek 1.5b in script Python o notebook Jupyter.
import ollama
response = ollama.chat(
model="deepseek-r1:1.5b",
messages=[
{
"role": "user",
"content": "Tell me an interesting fact about elephants",
},
],
)
print(response["message"]["content"])
La risposta è molto più lunga di 50 parole (ho testato anche la versione 32b con la stessa domanda, senza un miglioramento enorme).
Proseguiamo sul lato sviluppo.
Per streaming puoi usare AsyncClient:
import asyncio
from ollama import AsyncClient
async def chat():
message = {
"role": "user",
"content": "Tell me an interesting fact about elephants"
}
async for part in await AsyncClient().chat(
model="deepseek-r1:1.5b", messages=[message], stream=True
):
print(part["message"]["content"], end="", flush=True)
# Run the async function
async def main():
await chat()
# Check if there's a running event loop and use it, otherwise create a new one
try:
loop = asyncio.get_running_loop()
except RuntimeError:
loop = None
if loop and loop.is_running():
asyncio.ensure_future(main())
else:
asyncio.run(main())
Metodo 2: usare la API di Ollama
Se preferisci lavorare con API dirette o integrare Llama/DeepSeek in applicazioni non Python, Ollama offre una semplice API HTTP.
curl http://localhost:11434/api/chat -d '{
> "model": "deepseek-r1:1.5b",
> "messages": [
> {
> "role": "user",
> "content": "What are God Particles?"
> }
> ],
> "stream": false
> }'
Questo metodo è flessibile perché funziona da qualsiasi linguaggio o tool in grado di fare richieste HTTP.
Metodo 3: LangChain per applicazioni avanzate
Per use-case più complessi, soprattutto con analisi documentale e retrieval, LangChain si integra bene con Ollama e Llama 3.2.
Snippet con caricamento documenti, embeddings e similarity search su un articolo Wikipedia su Thomas Jefferson salvato in Word.
Assicurati di installare python-docx (es. pip install python-docx).
from langchain_community.document_loaders import DirectoryLoader, UnstructuredWordDocumentLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.llms import Ollama
from langchain_community.vectorstores import Chroma
# Load documents
loader = DirectoryLoader('/path/to/documents', glob="**/*.docx", loader_cls=UnstructuredWordDocumentLoader)
documents = loader.load()
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(documents)
# Create embeddings and vector store
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# Initialize LLama 3.2 1B
llm = Ollama(model="llama3.2:1b", base_url="http://localhost:11434")
# Perform a similarity search and generate a response
query = "What was the main accomplishment of Thomas Jefferson?"
similar_docs = vectorstore.similarity_search(query)
context = "\n".join([doc.page_content for doc in similar_docs])
response = llm(f"Context: {context}\nQuestion: {query}\nAnswer:")
print(response)
Risposta del modello:

Non perfetta, ma questo approccio permette di creare applicazioni che comprendono e ragionano su grandi quantità di testo usando la capacità linguistica di Llama, DeepSeek e altri modelli.
Conclusione
Eseguire localmente Llama 3.2, DeepSeek o altri modelli disponibili in Ollama apre molte possibilità per applicazioni IA.
Dalle chat semplici alle integrazioni API fino all’analisi documentale avanzata, questi tre metodi coprono un ampio spettro di use-case.
Usa questi strumenti in modo responsabile ed etico.