3 formas de ejecutar DeepSeek y Llama localmente
12 de febrero de 2025 · 4 min de lectura
Los Large Language Models (LLMs) han transformado el panorama de IA, y los modelos pequeños están creciendo con fuerza. Eso abre la posibilidad de ejecutar modelos avanzados incluso en PCs antiguos y smartphones. Como punto de partida, veremos tres métodos para usar Llama 3.3 o DeepSeek en local.
TL;DR
- Paquete Python: usa Ollama para chats simples o en streaming con modelos como
deepseek-r1:1.5b. - API: usa la API HTTP local de Ollama para integrar en cualquier lenguaje.
- LangChain: crea aplicaciones avanzadas (análisis documental y retrieval) con embeddings y vector stores.
Requisitos previos
Antes de empezar:
- Ollama instalado y en ejecución
Decisiones, decisiones...
¿Qué versión del modelo es lo bastante pequeña para tu equipo? Mi enfoque: probar. Empieza por la más pequeña y sube hasta ver cuántos parámetros aguanta tu máquina.
Para revisar versiones disponibles en Ollama: https://ollama.com/search.
Por ejemplo, para deepseek-r1, la más pequeña disponible es 1.5b. En terminal:
ollama pull deepseek-r1:1.5b
Obtenemos:
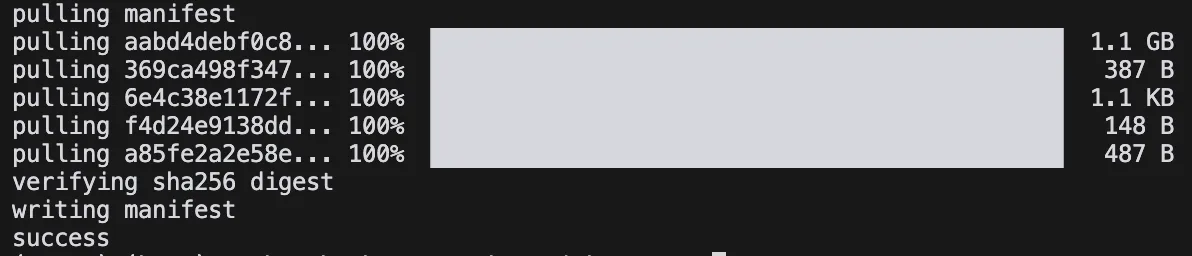
El modelo ocupa algo más de 1.1 GB. Bien.
Para probar rápido:
ollama run deepseek-r1:1.5b
Salida:
>>> Send a message (/? for help)
Enviemos un mensaje:
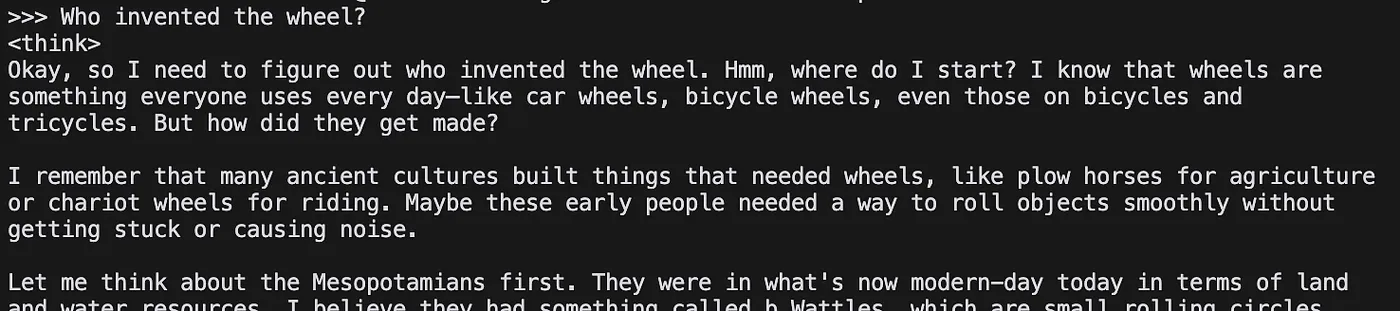
El resultado es bastante bueno.
Método 1: paquete Python de Ollama
El paquete Python de Ollama permite integrar DeepSeek 1.5b de forma directa en scripts Python o notebooks.
import ollama
response = ollama.chat(
model="deepseek-r1:1.5b",
messages=[
{
"role": "user",
"content": "Tell me an interesting fact about elephants",
},
],
)
print(response["message"]["content"])
La respuesta supera ampliamente 50 palabras (también probé la versión 32b con la misma pregunta, sin mejora enorme).
Sigamos con la parte de implementación.
Si quieres streaming, usa AsyncClient:
import asyncio
from ollama import AsyncClient
async def chat():
message = {
"role": "user",
"content": "Tell me an interesting fact about elephants"
}
async for part in await AsyncClient().chat(
model="deepseek-r1:1.5b", messages=[message], stream=True
):
print(part["message"]["content"], end="", flush=True)
# Run the async function
async def main():
await chat()
# Check if there's a running event loop and use it, otherwise create a new one
try:
loop = asyncio.get_running_loop()
except RuntimeError:
loop = None
if loop and loop.is_running():
asyncio.ensure_future(main())
else:
asyncio.run(main())
Método 2: usar la API de Ollama
Si prefieres APIs directas o integrar Llama/DeepSeek en apps que no sean Python, Ollama ofrece una API HTTP simple.
curl http://localhost:11434/api/chat -d '{
> "model": "deepseek-r1:1.5b",
> "messages": [
> {
> "role": "user",
> "content": "What are God Particles?"
> }
> ],
> "stream": false
> }'
Este método es flexible para cualquier lenguaje o herramienta que haga peticiones HTTP.
Método 3: LangChain para aplicaciones avanzadas
Para casos más complejos, en especial análisis documental y retrieval, LangChain se integra muy bien con Ollama y Llama 3.2.
Este snippet carga documentos, crea embeddings y hace búsqueda por similitud con un artículo de Wikipedia sobre Thomas Jefferson guardado en Word.
Asegúrate de instalar python-docx (por ejemplo pip install python-docx).
from langchain_community.document_loaders import DirectoryLoader, UnstructuredWordDocumentLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.llms import Ollama
from langchain_community.vectorstores import Chroma
# Load documents
loader = DirectoryLoader('/path/to/documents', glob="**/*.docx", loader_cls=UnstructuredWordDocumentLoader)
documents = loader.load()
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(documents)
# Create embeddings and vector store
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# Initialize LLama 3.2 1B
llm = Ollama(model="llama3.2:1b", base_url="http://localhost:11434")
# Perform a similarity search and generate a response
query = "What was the main accomplishment of Thomas Jefferson?"
similar_docs = vectorstore.similarity_search(query)
context = "\n".join([doc.page_content for doc in similar_docs])
response = llm(f"Context: {context}\nQuestion: {query}\nAnswer:")
print(response)
Respuesta del modelo:

No es perfecta, pero este método permite construir aplicaciones que entienden y razonan sobre grandes volúmenes de texto con la capacidad lingüística de Llama, DeepSeek y otros modelos.
Conclusión
Ejecutar localmente Llama 3.2, DeepSeek u otros modelos de Ollama abre muchas posibilidades para aplicaciones con IA.
Ya sea chat simple, integración vía API o análisis documental complejo, estas tres vías cubren muchos casos de uso.
Usa estas herramientas de forma responsable y ética.