3 Wege, DeepSeek und Llama lokal auszuführen
12. Februar 2025 · 4 Min. Lesezeit
Large Language Models (LLMs) haben die KI-Landschaft stark verändert, und kleine Modelle werden immer wichtiger. Dadurch wird es möglich, fortgeschrittene LLMs sogar auf älteren PCs und Smartphones lokal zu betreiben. Als Einstieg schauen wir uns drei Methoden an, um lokal mit Llama 3.3 oder DeepSeek zu arbeiten.
TL;DR
- Python-Paket: Nutze Ollama für einfache oder gestreamte Chats mit Modellen wie
deepseek-r1:1.5b. - API: Nutze Ollamas lokale HTTP-API für flexible Integration in jede Sprache.
- LangChain: Baue fortgeschrittene Anwendungen wie Dokumentanalyse und Retrieval mit Embeddings und Vector Stores.
Voraussetzungen
Bevor wir starten, brauchst du:
- Ollama installiert und laufend
Entscheidungen, Entscheidungen...
Welche Modellversion ist klein genug, um lokal auf deinem Rechner zu laufen? Mein Ansatz: Einfach ausprobieren! Starte mit der kleinsten Version und arbeite dich hoch, bis du weißt, wie viele Parameter dein System schafft.
Um verfügbare Versionen in Ollama zu sehen, besuche https://ollama.com/search.
Für deepseek-r1 sehen wir z. B., dass das kleinste verfügbare Modell 1.5b Parameter hat. Der Pull im Terminal:
ollama pull deepseek-r1:1.5b
Wir erhalten:
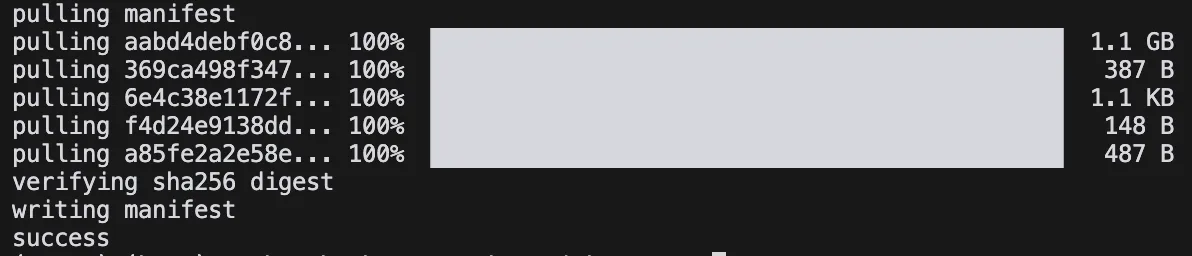
Das Modell ist etwas über 1.1 GB groß. Nicht schlecht.
Zum schnellen Test:
ollama run deepseek-r1:1.5b
Ausgabe:
>>> Send a message (/? for help)
Senden wir eine Nachricht:
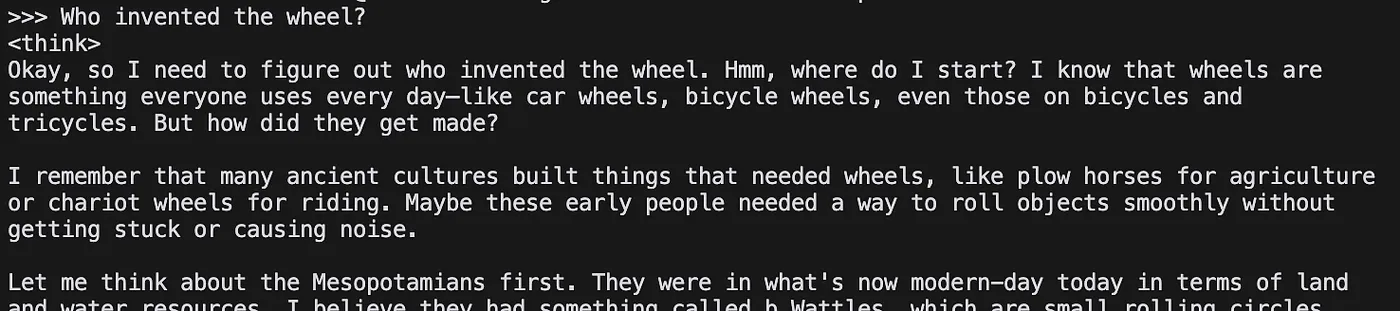
Das Ergebnis ist beeindruckend.
Methode 1: Ollama Python Package
Jetzt zu unseren drei Methoden. Das Ollama-Python-Paket bietet einen direkten Weg, um DeepSeek 1.5b in Python-Skripten oder Jupyter Notebooks zu verwenden.
import ollama
response = ollama.chat(
model="deepseek-r1:1.5b",
messages=[
{
"role": "user",
"content": "Tell me an interesting fact about elephants",
},
],
)
print(response["message"]["content"])
Die Antwort ist deutlich länger als 50 Wörter. (Ich habe übrigens auch die 32b-Version mit derselben Frage getestet, ohne deutlich bessere Qualität.)
Aber weiter mit dem Coding-Teil; Modellqualität ist nicht Fokus dieses Beitrags.
Die Methode oben ist gut für synchrone Interaktionen. Wenn du streamen willst, kannst du AsyncClient nutzen:
import asyncio
from ollama import AsyncClient
async def chat():
message = {
"role": "user",
"content": "Tell me an interesting fact about elephants"
}
async for part in await AsyncClient().chat(
model="deepseek-r1:1.5b", messages=[message], stream=True
):
print(part["message"]["content"], end="", flush=True)
# Run the async function
async def main():
await chat()
# Check if there's a running event loop and use it, otherwise create a new one
try:
loop = asyncio.get_running_loop()
except RuntimeError:
loop = None
if loop and loop.is_running():
asyncio.ensure_future(main())
else:
asyncio.run(main())
Methode 2: Ollama API
Wenn du lieber direkt mit APIs arbeitest oder Llama/DeepSeek in Nicht-Python-Apps integrieren willst, bietet Ollama eine einfache HTTP-API. Beispiel in Bash:
curl http://localhost:11434/api/chat -d '{
> "model": "deepseek-r1:1.5b",
> "messages": [
> {
> "role": "user",
> "content": "What are God Particles?"
> }
> ],
> "stream": false
> }'
Diese Methode ist flexibel, weil sie aus jeder Sprache oder jedem Tool mit HTTP-Requests nutzbar ist.
Methode 3: LangChain für fortgeschrittene Anwendungen
Für komplexere Anwendungsfälle, besonders mit Dokumentanalyse und Retrieval, integriert sich LangChain gut mit Ollama und Llama 3.2.
Der folgende Code zeigt das Laden von Dokumenten, Erzeugen von Embeddings und eine Similarity Search mit einem Wikipedia-Text über Thomas Jefferson, den ich als Word-Dokument gespeichert habe.
Dafür python-docx installieren (z. B. pip install python-docx).
from langchain_community.document_loaders import DirectoryLoader, UnstructuredWordDocumentLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.llms import Ollama
from langchain_community.vectorstores import Chroma
# Load documents
loader = DirectoryLoader('/path/to/documents', glob="**/*.docx", loader_cls=UnstructuredWordDocumentLoader)
documents = loader.load()
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(documents)
# Create embeddings and vector store
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# Initialize LLama 3.2 1B
llm = Ollama(model="llama3.2:1b", base_url="http://localhost:11434")
# Perform a similarity search and generate a response
query = "What was the main accomplishment of Thomas Jefferson?"
similar_docs = vectorstore.similarity_search(query)
context = "\n".join([doc.page_content for doc in similar_docs])
response = llm(f"Context: {context}\nQuestion: {query}\nAnswer:")
print(response)
Die Modellantwort:

Nicht perfekt, aber die Methode zeigt, wie du Anwendungen bauen kannst, die größere Textmengen mit der Sprachkompetenz von Llama, DeepSeek und anderen Modellen verarbeiten.
Fazit
Llama 3.2, DeepSeek oder andere Ollama-Modelle lokal zu betreiben, eröffnet viele Möglichkeiten für KI-Anwendungen.
Ob einfache Chats, API-Integrationen oder komplexe Dokumentanalyse: Diese drei Wege decken ein breites Spektrum an Anwendungsfällen ab.
Nutze die Tools verantwortungsvoll und ethisch. Happy coding!